# 后端知识
记录后端开发部分知识,子曰:“温故而知新,可以为师矣!”
- 技术知识
- Java开发生态圈
- 软件研发-Java系统知识图谱
- 业务场景解决方案
- 系统解决方案
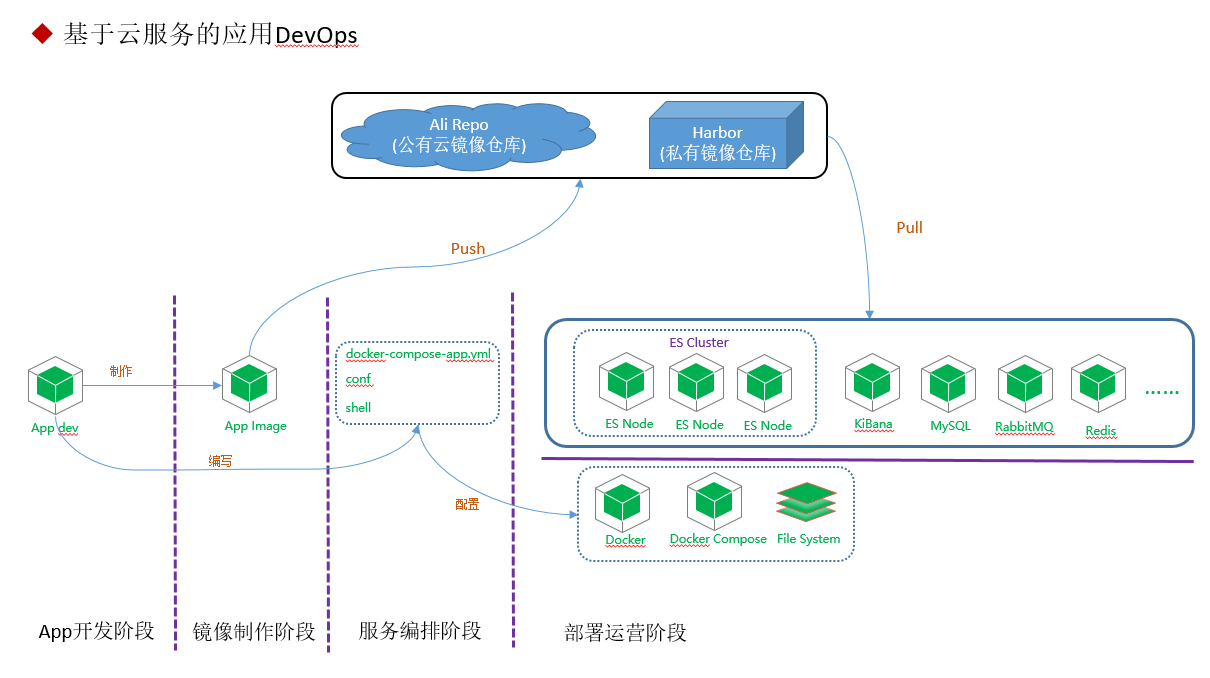 基于云服务的应用DevOps,是自己在实践中探索出来的一套DevOps,不知与其他大厂对比是否有多大差距,但目前应用在
自己的开发业务上,基本满足了,具体指标,还需进一步验证。
基于云服务的应用DevOps,是自己在实践中探索出来的一套DevOps,不知与其他大厂对比是否有多大差距,但目前应用在
自己的开发业务上,基本满足了,具体指标,还需进一步验证。
人工研判
临时记录
- Swagger-ui (opens new window): 后台接口监控,http://host:port/swagger-ui.html Knife4j (opens new window)
- Druid (opens new window): 数据库监控,http://host:port/druid/sql.html admin/admin
- Github开源项目地址 (opens new window)
开发工具
- IntelliJ IDEA 注册码 (opens new window)
- IntelliJ IDEA 工具教程 (opens new window)
- 天若OCR-图片文字识别工具 (opens new window)
- PanDownload-百度网盘破解下载 (opens new window)
- 永久激活IDEA 2019.2.3、PyCharm 2019.2.3、WebStorm 2019.2.3教程 (opens new window)
- Jetbrains系列产品2019.3.3最新激活方法(持续更新) (opens new window)
- Java 虚拟机 9:Java 类加载机制 (opens new window)
- JVM 史上最最最完整深入解析 (opens new window)
# 网站
- Java仓库链接、Python仓库链接、爬虫工具
- Twipu: Twitter信息同步网站 (opens new window)
- 自然美丽的高清图片下载网站 (opens new window)
- 小幺鸡| DocWay接口文档管理 (opens new window)
- 草料二维码:可以存放外部引用图片 (opens new window)
- LeanCloud:可免费创建数据库,存放聊天文本消息等 (opens new window)
# 算法类技术
# 工具类技术
- Apache基金会仓库(Kafka等所有工具下载地址) (opens new window)
- devops架构的优点 (opens new window)
- 落地DevOps (opens new window)
工具列表
- Web数据采集
- Docker:容器工具
- Dockerfile: Docker镜像制作文件(定义镜像生成具体步骤的文件)
- Docker-Compose:容器服务编排工具
- Harbor (opens new window):Docker私有镜像仓库管理工具
- Kubernates相关知识点:服务编排技术
- Docker Swarm简介:服务编排技术,Docker集群管理工具
- Git:版本控制工具
- Gitlab (opens new window):代码仓库管理工具
- Maven:项目管理工具
- ClickHouse:列式存储数据库
- ELK:日志管理工具(收集、存储、检索、分析、展示)
- Nacos (opens new window):配置管理工具
- Apollo (opens new window): 配置管理工具
- NSQ (opens new window): GO语言消息队列
- NATS (opens new window):
- RabbitMQ:消息队列
- Kafka: 使用Docker快速搭建Zookeeper和kafka集群 (opens new window)
- Regex101 (opens new window):正则表达式在线校验工具
- Jenkins:持续集成工具
- Sonatype Nexus (opens new window): Maven第三方依赖包私有仓库 安装教程 (opens new window),可以使用阿里云仓库
- Beam: 数据同步组件
- Grafana (opens new window): 开源监测平台
- Nginx: Web服务器
- Shardingsphere (opens new window):分布式数据库中间件,参考地址ShardingSphere 的开源之路 (opens new window)
- FastDFS: 分布式小文件存储技术
- Neo4j: 图数据库
- Redis: 内存数据库
技术分类列表
- 消息队列篇
- 关系型数据库
- MySQL
# Apache Beam
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink (opens new window)
- Apache Beam 实战指南之基础入门 (opens new window)
- Apache Beam官网 (opens new window)
- Beam API文档 (opens new window)
# Kafka
- kafka-connectors (opens new window)
- Kafka分区概念 (opens new window)
- Broker leader skew相关概念 (opens new window)
- Docker-compose部署zk集群、kafka集群以及kafka-manager,及其遇到的问题和解决 (opens new window)
- kafka的权限管理之ACL权限控制 (opens new window)
TIP
增加分区可以提供kafka集群的吞吐量,集群的总分区数或是单台服务器上的分区数过多,会增加不可用及延迟的风险。
broker leader skew会导致不同broker的读写负载不均衡
Broker Skew: 反映 broker 的 I/O 压力,broker 上有过多的副本时,相对于其他 broker ,该 broker 频繁的从 Leader 分区 fetch 抓取数据, 磁盘操作相对于其他 broker 要多,如果该指标过高,说明 topic 的分区均不不好,topic 的稳定性弱;
Broker Leader Skew:数据的生产和消费进程都至于 Leader 分区打交道,如果 broker 的 Leader 分区过多,该 broker 的数据流入和流出相对于 其他 broker 均要大,该指标过高,说明 topic 的分流做的不够好;
Under Replicated: 该指标过高时,表明 topic 的数据容易丢失,数据没有复制到足够的 broker 上。
单条数据大小平均2KB
(1) 集群配置,单节点连接,一个TopicMessageLog,一个分区(1-2)、1个生产者、1个消费者,2w条数据,花费961s,平均速率20.8条/s,kafka-manager监视速率 生产消息速率:10条/s(20KB/s);
(2) 集群模式,三个节点连接,一个TopicMessageLog,六个分区(6)、1个生产者、1个消费者,2w条数据,花费959s,平均速率20.8条/s,kafka-manager监视速率 生产消息速率:21条/s(40KB/s);
(3) 集群模式,三个节点连接,一个TopicMessageLog,就个分区(6-12)、1个生产者,11529条数据,花费26s,平均速率443条/s,kafka-manager监视速率 生产消息速率:405.57条/s(810KB/s);
(4) 集群模式,三个节点连接,一个TopicMessageLog,就个分区(12)、1个生产者,11529条数据,花费26s,平均速率443条/s,kafka-manager监视速率 生产消息速率:221条/s(442KB/s);
(5) 集群模式,三个节点连接,一个TopicMessageLog,就个分区(6)、1个生产者(连接3个节点),11529条数据,花费28s,平均速率411条/s,kafka-manager监视速率 生产消息速率:171条/s(342KB/s);
(6) 集群模式,三个节点连接,一个TopicMessageLog,就个分区(6)、1个生产者(连接1个节点),11529条数据,花费25s,平均速率461条/s,kafka-manager监视速率 生产消息速率:216条/s(432KB/s);
测试结果,单机节点的kafka集群模式,处理速度太低,不适合作为目前线上环境(网络环境太差)的消息队列。下一步,采用三台服务节点再测试一下,如果还不行,就使用NSQ队列。
# NSQ
- NSQ官网 (opens new window)
- 快速搭建NSQ集群 (opens new window)
- Logstash配置NSQ插件:logstash-input-nsq (opens new window)
- Logstash Plugin (opens new window)
实时分布式消息传递平台
(1) 单机模式,单节点连接,一个TopicMessageLog(程序自动创建),1个生产者、1个消费者,11529条数据,花费13.29s,平均速率867.49条/s(1735KB/s); (1) 单机模式,单节点连接,一个TopicMessageLog(已提前创建),1个生产者、1个消费者,11529条数据,花费13.43s,平均速率858. 45条/s(1717KB/s);
nsq在docker部署后nsqadmin无法resolve所有nsqd的host的解决方法 (opens new window)
其他厂家也是这种配置,只是在机器查找方面配置的时IP地址,即nsqlookupd Host: nsqlookupd:4161 其他家配的时 192.168.2.106:4161,也是单机节点。 他们称之为平台。
nsqlookupd 为查找nsqd节点(一般部署双节点)
nsqd 为实际处理消息的节点,可以部署多个(一般部署3个节点以上,在哪个节点上生产的消息,就得在那个节点上消费)
nsqadmin 为管理的UI界面(一般部署双节点)
为Logstash而写插件:logstash-input-nsq (opens new window)
注意:Docker容器中的地址必需暴露出来,否则logstash可能会消费不了消息
version: '3'
services:
nsqlookupd:
image: nsqio/nsq
command: /nsqlookupd --broadcast-address=192.168.2.106 # 暴露nsqlookup地址
ports:
- "4160:4160"
- "4161:4161"
nsqd-01:
image: nsqio/nsq
command: /nsqd --lookupd-tcp-address=192.168.2.106:4160 --broadcast-address=192.168.2.106 # 暴露nsq地址
depends_on:
- nsqlookupd
ports:
- "4150:4150"
- "4151:4151"
nsqadmin:
image: nsqio/nsq
command: /nsqadmin --lookupd-http-address=192.168.2.106:4161
depends_on:
- nsqlookupd
ports:
- "4171:4171"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# NATS
- 高性能消息中间件——NATS (opens new window)
- Nats Streaming Spring (opens new window)
- 轻量消息中间件NATS与NSQ的介绍和比较 (opens new window)
# Shardingsphere
ShardingSphere官网 (opens new window)
- 分表与分库使用场景以及设计方式 (opens new window)
- 分库分表、分区、读写分离 这些都是用在什么场景下,会带来具体的哪些好处 (opens new window)
- 分库分表是什么,什么情况下需要用分库分表 (opens new window)
- ShardingSphere 的开源之路 (opens new window)
# Grafana
监控 Metrics
# MySQL
# 基本概述
Java方面
- 基于Java基础知识,基础概念、面向对象概念、条件判断、集合类、流编程、网络编程、
- Java虚拟机原理
- Java高级特性和类库
- Java网络与服务器编程
- Java多线程编程以及常见开源产品
Spring方面
高级部分
- 分布式系统原理:CAP、最终一致性、幂等操作等;
- 大型网络应用架构:消息中间件、缓存、负载均衡、集群技术、数据同步;高可用、可容灾分布式系统设计能力。
- 具备模块或子系统的架构设计能力,掌握常见的架构设计方法和模式,理解大型网站所需要用到的架构和技术。
- 能独立解决问题,能够负责重要业务模块的需求分析及设计实现,且对线上部署环境比较熟悉,能够独立分析和快速排查线上故障。
TODO(SpringCloud、大数据生态圈、业务行业发展方向及趋势)